第1回:今あるプログラムを楽に速くするためには?
「GPUが速いのは知ってるけれど、GPUプログラミングは難し過ぎる!」と思っているそこのあなた!
OpenACCという並列プログラミングモデルをご存じでしょうか。
OpenACCは、GPUプログラミング(正確には演算加速装置向けのプログラミング)をより楽にするために開発された並列プログラミングモデルです。
OpenACCは、以下のような方にお勧めです。
- これからGPUプログラミングを始める初心者の方
- GPUプログラミングの工数をとにかく減らしたい私のような方
本記事は主に前者の人に向けて、OpenACCを紹介します。
そもそもなぜ、GPUプログラミングは難しいのか
わざわざGPUプログラミングをする目的は、プログラムの高速化にあるわけですよね?
しかしプログラムの高速化というのは、それだけで一研究分野(高性能計算という)を築けてしまうくらい複雑なのです。
とりわけGPUは数千個の演算コアを扱う並列計算が必須です。
演算コアというのは、足し算や引き算などをしてくれる小人さんだと思ってください。

GPUの高い性能は、小人さん全員の力を合わせることで実現されますから、数千人の小人さんに効率良く仕事を分散する、並列プログラミングが必須となります。
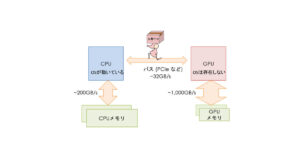
この並列プログラミングというのがとても難しいのです!(図1)
ではなぜ、OpenACCは簡単か
OpenACCが簡単な理由は単純です。
OpenACCでは難しい並列処理を書けないからです!
その代わり、OpenACCの型にはまった並列処理であれば、非常にシンプルに記述できます。
型にはまった処理というのは、①小人さんそれぞれの担当領域で、②全員同じ仕事をする並列処理のことです(図2)。

(庭の草むしりなどのイメージ)
逆に書けない難しい並列処理というのは、小人さん同士のコミュニケーションを必要とする処理です。
小人1の仕事が終わったら小人2が~なんて処理は、小人1が「終わったよ!」と声を掛ける必要がありますから、OpenACCでは基本的には書けません。
具体的には、どんな処理ならOpenACCで書けるのか
通常、GPUでの高速化は、プログラム中の重たいループ構造を並列実行することで達成します(図3)。
OpenACCでもループ構造を並列化しますが、前述のとおり制限があります。
NVIDIA社のGPU向けの専用言語、CUDAと比較してみましょう。

ループ構造部分のみ抜き出して、GPUに処理を任せる。
まず前提として、なんでもかんでもGPUで高速化できるわけではありません(図4)。
GPUで高速化可能なのは世の中にあるループの一部であり、OpenACCで高速化可能なループは、さらにその一部に過ぎません。

OpenACCでは、GPUで高速化可能なループを以下の3つに分類します(図5)。
- データ独立なループ
- リダクション(縮約演算)ループ
- それ以外(データ依存のあるループ)

データ独立なループとは、ちょうど図2のように並列処理可能なループです。
ループの i番目の処理をi番の小人さんが担当するとしましょう。
すると、配列AとBとCの i番目の要素が、i番の小人さんの担当領域になります。
そしてこの担当領域は、他の小人さんと独立¹ ですね?
¹ ただし、配列AとBとCがaliasを持たない場合。Aliasについては後日解説。
データ独立なループは、ループをどのような順序で実行しても結果が変わらないという特徴があるため、明らかに並列実行できます。
OpenACCであれば非常に簡単に並列化できますし、CUDAでも頭を使わずに並列化できます(記述量が多く面倒だけど)。
もう一つ、リダクション(縮約演算)タイプのループ(図5中央)があります。
例によってループの i番目の処理を i番の小人さんが担当すると、sumは全員の担当領域となるため、依存関係があるように見えます。
しかし足し算の性質上、どのような順序でループを実行しても答えは変わりません。
このようなループも、OpenACCでは非常に簡単に並列化できます。一方、CUDAを使ってリダクションを実装するのは、非常に難しいです。
一方で、図5の一番右、データ依存のあるループの場合はどうでしょう。
同じようにループの i番目の処理を i番の小人さんが担当するとしましょう。
すると、i番目の小人さんが担当する領域B[i+1], B[i]と、i+1番目の小人さんが担当する領域B[i+2],B[i+1]が一部重なってしまいます。
このループを正しく実行するためには、i番目の小人さんの計算が終わってから、i+1番目の小人さんが計算しなくてはなりません。こういったループは、ループの実行順に依存関係があり、並列化が困難なループです。
OpenACCで高速化するのはほぼ不可能ですが、CUDAであれば、shared memoryやwarp shuffleと呼ばれるGPUの機能を駆使することにより、高速実装可能です(これを自在に実装できる人々をCUDAエキスパートと呼びます)。
OpenACCには大きな制約があるようだが、OpenACCでGPUプログラミングを始めて大丈夫か
NVIDIAのGPUをターゲットとするなら、最終的にはOpenACC+CUDAという書き方が推奨です。
OpenACCは初めからそれを前提として設計されていて、簡単にCUDAと組み合わせることができます。
数値計算を行うアプリケーションは多数のループから成りますが、経験的にそのほとんどはデータ独立なループやリダクションループです。
まずOpenACCでアプリケーションのGPU向け実装を進め、それで満足な性能が得られればそれでいいですし、データ依存のあるループのせいなどで性能が十分でないならば、その部分のみをCUDA化するなり、ライブラリを呼び出すなりすれば良いのです。
データ独立なループとリダクションループに限れば、OpenACC実装の性能はCUDAと遜色なく、圧倒的にシンプルに記述できます。故にCUDAエキスパートであっても、工期短縮のためにOpenACCも利用しているのです。
結局CUDAも覚えなくてはならないようだというのはネガティブな情報かもしれませんが、OpenACCを覚えておけばかなり楽ができますので、一緒に覚えていきましょう。
次回以降は、具体的なOpenACCの使い方について解説していきます。