第3回:データ転送の最小化はほとんどのアプリケーションで必須
前回は、図1のプログラムを例にして、OpenACCの主要な3つの指示文:kernels, data, loop指示文を紹介しました。
今回はプログラムの効率について考えてみましょう。

OpenACCによるデータ転送の最小化
OpenACCを使うからには、元のCPU向けのプログラムより速くならなきゃ意味がないですよね!
しかしOpenACCには、答えは正しいものの非常に遅いプログラムを簡単に書けてしまうという落とし穴があります。
例えば、図1の5行目のdata指示文を、6行目のfor文の内側、7行目のkernelsのすぐ上に記述したらどうなるでしょう。
このような変更を行った場合、15行目のprintfで出力される答えは変わらないにも関わらず、100倍近く遅くなってしまいます!
理由は簡単。
本来1回でよかったはずのdata指示文によるデータ転送を、tのループで100回繰り返してしまうからです。
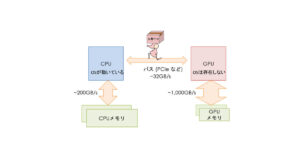
前回と同じ図(図2)をもう一度掲載します。
これを見てもらえればわかるように、CPUとGPUの間のデータ転送性能は、CPUのメモリのデータ転送性能より低いのです。
つまり、GPUで計算を行う度にデータ転送を行っていては、CPUより速くなるはずがないのです!

長くて狭い道を通らなくてはならない!
さて、それを踏まえてうえで、もう一度図1の効率化を考えてみましょう。
このプログラムでは4行目のループで配列aを初期化していますが、これ、わざわざCPUでやる必要はないですよね?
図3のように修正してみましょう。

これで、図1の4行目のループがGPUで並列実行されます(図3の6-8行目)。
それによっても多少速くなりますが、ここで重要なのはdata指示文の変化です。
まず、初期化部分を並列化したことに伴い、data指示文がその部分もカバーするように移動したことがわかります。
さらにdata指示文の指示子がcopyからcopyoutに変更されています。copyと指定された配列は、data指示文の始まりでCPUからGPUへ、終わりでGPUからCPUへコピーされますが、copyoutの場合にはGPUからCPUへのコピーのみが行われます。
図3では配列aの初期化をGPUで行っていますから、CPUからGPUへのコピーは必要ないのです。この修正を行うことで、CPU-GPU間のデータ転送コストを半分にすることができました!
この調子で、sumを計算するループについても並列化してしまいましょう。図4です。

Sumを計算するループは、リダクションと呼ばれる演算パターンですね。
データ独立ではないのでindependent指示子は指定できませんが、reduction指示子を使うことで並列化することができる特殊なパターンです。
詳しくは次回以降に解説しますが、変数sumのCPU-GPU間のデータ転送はOpenACCが勝手にやってくれます。
重要なのはまた、data指示文の変化です。
リダクションループを囲むように移動したのと同時に、今度はcopyoutからcreateに代わっています。
createと指定された配列はGPU上にmallocされるだけで、CPU-GPU間のコピーは一切行われません。
このプログラムでは変数sumの値さえわかれば配列aは必要ないわけですから、GPUからCPUへのデータコピーも必要ないわけです。変数sumのデータコピーは勝手に行われているわけですが、10万要素の配列aをコピーするよりは遥かに短い時間で済みます。
これによって、CPU-GPU間のデータ転送はほぼ削減できました!
ちなみに、data指示文の指示子には以下のようなものがあります。
これらは、メモリ領域の確保(malloc)、CPUからGPUへの入力(CPU->GPU)、GPUからCPUへの出力(CPU<-GPU)、メモリ領域の開放(free)の組み合わせです。
- Copy : malloc, CPU->GPU, CPU<-GPU, free
- Copyin : malloc, CPU->GPU, free
- Copyout : malloc, CPU<-GPU, free
- Create : malloc, free
データ転送の最小化はほとんどのアプリケーションで必須!
今回扱ったのは、main文ひとつの非常に小さなプログラムでしたが、多くのシミュレーションプログラムでも同じような手順でOpenACC実装を進めていきます。
多くの数値シミュレーションでは、時間発展のループが一番外側にあり、その内側で例えばx,y,zの三重ループを並列化します。
従って、データの転送を最小化するためには、時間発展ループの外側まで、data指示文を追いやる必要があるのです。
次回以降、簡単な拡散方程式を題材として、OpenACC化の解説を行います。
1ヵ月間有効のスパコンお試しアカウント
東京大学情報基盤センターでは、教育の一環として、制限はあるものの一ヵ月の間有効なスパコンアカウントを提供しています。
現在3つのスパコンが運用されていますが、そのうちReedbushと呼ばれるスパコンには、一世代前のものではありますがGPUが搭載されていて、OpenACCを使える環境も整っています。
自分でどんどん自習したい場合は、ご利用を考えてみてください。
また、東大センターが行った過去のOpenACCに関する講習会の資料やプログラムも公開されていますので、自習する場合にはぜひご利用ください。
トライアルアカウント申し込みページ
https://www.cc.u-tokyo.ac.jp/guide/trial/free_trial.php
講習会ページ
https://www.cc.u-tokyo.ac.jp/events/lectures/
講習会で用いているプログラム
https://www.dropbox.com/s/z4fmc4ibdggdi0y/openacc_samples.tar.gz?dl=0