第5回:コンパイラのメッセージを確認しよう
前回に引き続き、拡散方程式のプログラムを例として、OpenACCの使い方を学びます。
コンパイラのメッセージを確認しよう

図1は前回作成した疑似コードです。
なお、実際のコードはこちらよりダウンロードできます。
では、PGIコンパイラ (ver. 19.10) を用いて、このプログラムをコンパイルしてみましょう。
コンパイル時に出力されるメッセージが図2です。

実は、OpenACCのプログラムを実装する上で非常に重要なのが、コンパイル時に出力されるメッセージの確認 です。
これにより、OpenACCプログラムが意図したとおり並列化されているかどうかを確認します。
順番に説明します。
まずは1行目のコンパイルコマンドについて。
| pgcc | PGIのC言語用コンパイラです。Fortranの場合にはpgfortranを使います。 PGIのサイト(https://www.pgroup.com/products/community.htm)で登録を行えば無料でダウンロードできます。 |
| -O3 | コンパイラの自動最適化のレベルを3(最大)にするためのオプションです。 |
| -acc | OpenACCを有効化するためのオプションです。 OpenACCプログラムでは必須です。 |
| -Minfo=accel | コンパイラメッセージの出力を有効化するためのオプションです。 プログラムの性能には影響を与えませんが、OpenACCのプログラム実装では必須です。 |
| -ta=tesla,cc60 | ターゲットアーキテクチャ、要はGPUの種類を指定します。 tesla,cc60は、Tesla P100 GPU向けのオプションで、使うGPUによって変わります。 |
次に、2行目以降のコンパイラが出力するメッセージについて。
| diffusion3d | OpenACC指示文の挿入された関数名が表示されます。 今回はdiffusion3dです。 |
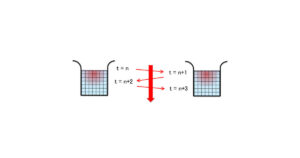
| 19, Generating copyout… | コードの19行目で、data指示文によるデータ転送が発生することを意味します。 [if not already present] とあるのは、もしGPU上に対象のデータがなければデータ転送処理をしますよ。という意味で、逆に言えばすでにデータがある場合にはなにもしないことを意味します。 つまり、図3のようにデータ転送が入れ子状になっていた場合、内側のデータ転送指示は無視されます。 |

| 21~25, Loop is parallelizable | 21, 23, 25行目のループ(図1でloop independentとした5, 7, 9行目に相当)がデータ独立で並列化可能と判断されたことを意味します。 Loop independentが正しく指示されている場合にこのように表示されます。 ちなみにindependent指示子を付けず、単に#pragma acc loopとした場合、データ独立なループであるかどうかはコンパイラが判断することになりますが、特にC言語の場合にはデータ独立であるかどうかを見切れないことが多いです。 その場合、Complex loop carried dependence of … といったメッセージが表示されます。 |
| Generating Tesla Code | コンパイルオプションに-ta:tesla,cc60を付けたことで、Tesla GPU 向けのカーネルが生成されたことを意味します。 カーネルの中身について、その下に続きます。 |
| #pragma acc loop gang …, vector … | 実はloop指示文には、independent, reductionなど、loopの種類を指示する以外にも、gang, worker, vector といった指示子を使い、並列化されたループをどのようにGPUにマッピングするかを指示することができます。 しかしこれを適切に設定するには、GPUのハードウェアを理解している必要があり、非常に難しい です。幸い、未指定の場合にはコンパイラが経験に基づき自動で設定してくれますので、それに頼ってしまって構いません。 以下の説明を現時点で理解する必要はありませんが、一応解説しておきます。 この問題の場合には、NX*NY*NZの直方体を、32*4*1の直方体で分割しています(図4)。 32と4はそれぞれvectorの値に相当し、ひとつのvectorはGPUのひとつのコアによって実行されます。 なぜ32かというと、GPUは32個のコアがひとつの塊として同時に動くという特徴があり、32の倍数は都合が良いからです。 この複数のvectorからなる塊をgangと呼びます。ひとつのgangは、ひとつのStreaming Multiprocessor (SM)と呼ばれる、32の倍数個(GPUの世代によって異なる)のコアからなるハードウェアに割り当てられます。 SMはキャッシュと呼ばれる高速なメモリを搭載しており、SM内の別のスレッドがアクセスしたデータについては、高速に共有することができます。 Y軸方向に4の幅を持たせているのは、キャッシュの利用効率を高めるためです。ひとつのSMには複数のgangを割り当てることができるので、GPUが持つ数十のSMで全体を分散処理します。 |

… おわかりいただけましたでしょうか。
今回は、コンパイラが出力するメッセージを元に、内部的にはどのようなことが行われているのかについて触れました。
これらはCUDAで実装する場合にはすべて自分で行う必要があるものです。
従って、ゆくゆくは理解した方が良いことではあります。
意図したとおりに並列化されているか確認するため、またOpenACCについての理解を助けるためにも、コンパイラのメッセージを必ず確認しましょう。
1ヵ月間有効のスパコンお試しアカウント
東京大学情報基盤センターでは、教育の一環として、制限はあるものの一ヵ月の間有効なスパコンアカウントを提供しています。
現在3つのスパコンが運用されていますが、そのうちReedbushと呼ばれるスパコンには、一世代前のものではありますがGPUが搭載されていて、OpenACCを使える環境も整っています。
自分でどんどん自習したい場合は、ご利用を考えてみてください。
トライアルアカウント申し込みページ
https://www.cc.u-tokyo.ac.jp/guide/trial/free_trial.php
< 過去の講習会の資料やプログラム公開中 >
東大センターが行った過去のOpenACCに関する講習会の資料やプログラムも公開されていますので、自習する場合にはぜひご利用ください。オンライン講習会 定期開催中!
講習会ページ
https://www.cc.u-tokyo.ac.jp/events/lectures/
講習会で用いているプログラム
https://www.dropbox.com/s/z4fmc4ibdggdi0y/openacc_samples.tar.gz?dl=0