[No.1] Googleは4月からオフィスを再開、社員はリモートワークを終了しハイブリッド勤務となる
Googleは4月1日からオフィスを再開し、一部の社員はリモートワークを終え、会社に戻り始めた。
9月1日からは全社員がハイブリッド勤務となり、週三日オフィスに出勤する勤務体系となる。
社員はワクチン接種が求められ、また、オフィスはリモデルされ、安全を担保しての勤務となる。
Facebookは無期限で在宅勤務を続けるが、Googleは人間同士のつながりを重視し、出社勤務が基本パターンとなる。

オフィスを再開
Googleはコロナの感染拡大とともにいち早く勤務形態をリモートワークとしたが、コロナの終息が視野に入る中、他社に先駆けて4月1日にオフィスを再開した。
希望する社員はオフィスに出社して勤務できる。オフィスはリモデリングされ、感染防止対策が取られた。
また、社員はワクチン接種が求められ、安全を考慮したうえでのオフィス勤務となる。
コロナ後の勤務形態
9月1日からは、新しい勤務体系となり、全ての社員はハイブリッドで仕事をする。
週三日が出勤日で、社員は改装されたオフィスに出社して、従来のように対面で仕事をする。
これが基本形態で、年間14日を超えて在宅勤務を希望する社員は、要望書を会社に提出する。認可されれば在宅勤務を継続できるが、必要に応じて、出社を求めることがあるとしている。
コロナ終息後は、Googleはハイブリッド勤務で事業を進めることが明らかになった。(下の写真、建設中の本社ビルで今年中にオープンする予定。また、Googleは本社周辺のオフィスビルの買収を進めている。リモートワークで余った物件を買い進めオフィススペースを拡大中。)
勤務地と給与
ハイブリッド勤務になると居住地についての制限はないが、Googleは社員が住んでいる地域の物価に合わせて給与を調整するとしている。
郊外の物価が安い街に住むと生活費の負担が減るが、それに合わせて給与が下がることになる。このため、Googleは多くの社員がシリコンバレーに戻ってくるとみている。
まだ在宅勤務が続いているが、シリコンバレーを離れ地方都市で暮らしている社員は少なくない。

出社勤務に戻す理由
Google最高経営責任者Sundar Pichaiは、当初から、リモートワークにおける仕事の効率や生産性について疑問視していた。
リモートワークではチームワークの形成が難しく、特に、新製品開発でイノベーションが求められるが、遠隔ではやりにくい。
また、在宅勤務では製品情報など社内の機密情報が外部に流出する危険性も含んでいる。
このため、Googleは社員を会社勤務に戻すが、柔軟な勤務方式も維持し、週2日は在宅勤務を認める。
社員の勤務形態に関する嗜好
社員はリモートワークに魅力を感じるとともに、在宅勤務では仕事の限界を感じ、オンラインでのコミュニケーションでストレスが蓄積している。
完全在宅勤務を選択する社員の割合は少なく、柔軟なワークスタイルを維持できるハイブリッド勤務を求めている。
Facebookなど
一方、FacebookやTwitterなどはコロナが終息しても、無期限で在宅勤務を続けるとしている。
希望する社員はオフィス勤務に戻ることができるが、リモートワークが勤務体系の基本パターンとなる。
また、社員は居住地を自由に選ぶことができ、環境がいい郊外に引っ越しできる。Facebookの狙いは人事採用にあり、リモートワークに移行することで、北米で幅広く優秀な人材を雇い入れることを目論んでいる。
シリコンバレーから人が流出
このように、社員が居住地を自由に選べるようになり、シリコンバレーから人が流出している。
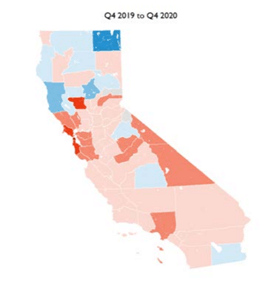
UC BerkeleyとUCLAの研究組織California Policy Labによると、2020年はサンフランシスコから流出する人の数が前年と比べ30%増加した。
一方、人口流入はコロナ以前と同じレベルで、結果として、2020年は流出人口が増えた年となった。(下のマップ、2020年第四四半期の人口流出の割合を示している。赤色の部分が人口流出が多い地域。)。
ポストコロナの勤務形態
米国はコロナの感染者数が世界最悪のレベルにあるが、バイデン政権になり感染者数が急速に減少し、ワクチン接種が急ピッチで進んでいる。
このペースで行くと夏までに国民の大部分がワクチン接種を完了すると予想されている。
コロナ終息が視野に入る中、IT企業はオフィスを再開し始めた。多くの企業がハイブリッド勤務を選んでおり、ポストコロナの勤務形態が見えてきた。
ただ、ハイブリッド勤務は今までに経験したことのないワークスタイルで、これから各社は試行錯誤しながら最適なモデルを生み出すことになる。
