
深層学習による地形画像解析
著者:佐藤 周平先生/法政大学 准教授、GPUと生成AIの進化により、単一画像から山岳風景の形状・照明・材質を再構築。再照明とセグメンテーションで自然地形解析に挑む最新研究を紹介。

GPUを用いた光害の可視化とその応用 ─ SIGGRAPH Asia発表論文解説
著者:土橋 宜典 先生/北海道大学 教授、GPUを活用した光害の可視化技術を解説!プロメテックCGリサーチがSIGGRAPH ASIA 2023で発表した最新研究を紹介。光の散乱計算をGPUで高速化し、夜空のリアルなレンダリングを実現する手法を詳しく解説。

再サンプリングを利用した画像生成手法
著者:岩崎 慶 先生/埼玉大学 教授
近年、CGによる画像生成手法として、パストレーシング(経路追跡法)を代表としたモンテカルロ法ベースの手法が広く使用されてきています。モンテカルロ法ベースの手法は最近ではゲームやVR向けのリアルタイムレンダリングにおいても主流となりつつあります。
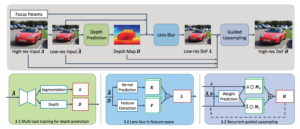
深層学習を利用した画像処理・画像認識と必要なGPU性能
著者:石川 知一 先生/東洋大学 准教授
ご存じの通り、深層学習(Deep Learning)は様々な分野に応用されています。この技術発展はGPUの性能向上と共にあります。本稿では画像処理、画像認識の分野において、最新の研究ではどのようなことを実現できるかと、実際に学習を行うために必要なGPUの性能についてまとめていきます。

トランスフォーマー 最近流行のニューラルネットワーク
著者:北岡 伸也 氏/Dwango Media Village
本稿では、どういう場面でどのようなニューラルネットワークのアーキテクチャーが使われるかはなんとなく知っているけど、実際に使ったり実装してみたりしたことはないといった方を対象として、では実際にそれはどのような仕組みで計算されているのかについてトランスフォーマー(Transformer)を題材として解説します。

GAN Inversion による写実的画像生成の制御
著者:金森 由博 先生/筑波大学 准教授
深層学習 (Deep Learning) で画像を作る、というと「GANってやつを使うんでしょ?」とお察しの方も多いかと思います。
今回はそのGAN (Generative Adversarial Network; 敵対的生成ネットワーク) についてですが、特に最近、研究分野でホットな “GAN Inversion” という技術をご紹介します。
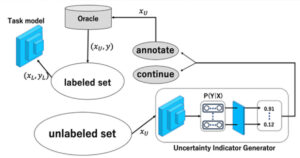
深層学習におけるアノテーションコストを抑えるための取り組み"Active Learning" について
著者:青木 義満 先生/慶應義塾大学 教授
近年、画像センシング分野における研究開発の成果は、深層学習の進化により、実社会の様々な場面で利活用されています。
機械学習、特に深層学習においては、ネットワークモデルの学習において、大規模な教師データ(ラベル付きデータ)が必要となります。

深層学習に基づく人物画像の再照明
著者:金森 由博 先生/筑波大学 准教授
本稿では画像を対象とした深層学習の応用事例のうち、我々にとって最も身近な人物画像を対象として、「再照明」という技術をご紹介します。

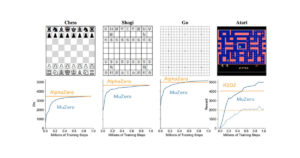
AlphaGo とその後
著者:北岡 伸也 氏/Dwango Media Village
Google DeepMindによって開発されたコンピューター囲碁プログラムであるAlphaGo(アルファ碁)が、2016年3月のイベントで人間を超える強さを示したことは、大きな衝撃を持って世界に伝えられ、人工知能技術に注目をあつめる契機となりました。